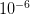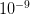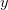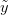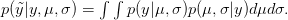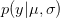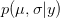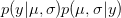I have recently read the latest book by Nassim Nicholas Taleb, Antifragile. I read his famous The Black Swan a while back while in the field and wrote lots of notes. I never got around to posting those notes since they were quite telegraphic (and often not even electronic!), as they were written in the middle of the night while fighting insomnia under mosquito netting. The publication of his latest, along with the time afforded by my holiday displacement, gives me an excuse to formalize some of these notes here. Like Andy Gelman, I have so many things to say about this work on so many different topics, this will be a bit of a brain dump.
Taleb's work is quite important for my thinking on risk management and human evolution so it is with great interest that I read both books. Nonetheless, I find his works maddening to say the least. Before presenting my critique, however, I will pay the author as big a compliment as I suppose can be made. He makes me think. He makes me think a lot, and I think that there are some extremely important ideas is his writings. From my rather unsystematic readings of other commentators, this seems to be a pretty common conclusion about his work. For example, Brown (2007) writes in The American Statistician, "I predict that you will disagree with much of what you read, but you'll be smarter for having read it. And there is more to agree with than disagree. Whether you love it or hate it, it’s likely to change public attitudes, so you can't ignore it." The problem is that I am so distracted by all the maddening bits that I regularly nearly miss the ideas, and it is the ideas that are important. There is so much ego and so little discipline on display in his books, The Black Swan and Antifragile.
Some of these sentiments have been captured in Michiko Kakutani's excellent review of Antifragile. There are some even more hilarious sentiments communicated in Tom Bartlett's non-profile in the Chronicle of Higher Education.
I suspect that if Taleb and I ever sat down over a bottle of wine, we would not only have much to discuss but we would find that we are annoyed -- frequently to the point of apoplexy -- by the same people. Nonetheless, I find one of the most frustrating things about reading his work the absurd stereotypes he deploys and broad generalizations he uses to dismiss the work of just about any academic researcher. His disdain for academic research interferes with his ability to make cogent critique. Perhaps I have spent too much time at Stanford, where the nerd is glorified, but, among other things, I find his pejorative use of the term "nerd" for people like Dr. John, as contrasted to man-of-his-wits Stereotyped, I mean, Fat Tony off-putting and rather behind the times. Gone are the days when being labeled a nerd is a devastating put down.
My reading of Taleb's critiques of prediction and risk management is that the primary problem is hubris. Is there anything fundamentally wrong with risk assessment? I am not convinced there is, and there are quite likely substantial benefits to systematic inquiry. The problem is that the risk assessment models become reified into a kind of reality. I warn students – and try to regularly remind myself – never to fall in love with one's own model. Something that many economists and risk modelers do is start to believe that their models are something more real than heuristic. George Box's adage has become a bit cliche but nonetheless always bears repeating: all models are wrong, but some are useful. We need to bear in mind the wrongness of models without dismissing their usefulness.
One problem about both projection and risk analysis, that Taleb does not discuss, is that risk modelers, demographers, climate scientists, economists, etc. are constrained politically in their assessments. The unfortunate reality is that no one wants to hear how bad things can get and modelers get substantial push-back from various stakeholders when they try to account for real worst-case scenarios.
There are ways of building in more extreme events than have been observed historically (Westfall and Hilbe (2007), e.g., note the use of extreme-value modeling). I have written before about the ideas of Martin Weitzman in modeling the disutility of catastrophic climate change. While he may be a professor at Harvard, my sense is that his ideas on modeling the risks of catastrophic climate change are not exactly mainstream. There is the very tangible evidence that no one is rushing out to mitigate the risks of climate change despite the fact that Weitzman's model makes it pretty clear that it would be prudent to do so. Weitzman uses a Bayesian approach which, as noted by Westfall and Hilbe, is a part of modern statistical reasoning that was missed by Taleb. While beyond the scope of this already hydra-esque post, briefly, Bayesian reasoning allows one to combine empirical observations with prior expectations based on theory, prior research, or scenario-building exercises. The outcome of a Bayesian analysis is a compromise between the observed data and prior expectations. By placing non-zero probability on extreme outcomes, a prior distribution allows one to incorporate some sense of a black swan into expected (dis)utility calculations.
Nor does the existence of black swans mean that planning is useless. By their very definition, black swans are rare -- though highly consequential -- events. Does it not make sense to have a plan for dealing with the 99% of the time when we are not experiencing a black swan event? To be certain, this planning should not interfere with our ability to respond to major events but I don't see any evidence that planning for more-or-less likely outcomes necessarily trades-off with responding to unlikely outcomes.
Taleb is disdainful about explanations for why the bubonic plague didn't kill more people: "People will supply quantities of cosmetic explanations involving theories about the intensity of the plague and 'scientific models' of epidemics." (Black Swan, p. 120) Does he not understand that epidemic models are a variety of that lionized category of nonlinear processes he waxes about? He should know better. Epidemic models are not one of these false bell-curve models he so despises. Anyone who thinks hard about an epidemic process -- in which an infectious individual must come in contact with a susceptible one in order for a transmission event to take place -- should be able to infer that an epidemic can not infect everyone. Epidemic models work and make useful predictions. We should, naturally, exhibit a healthy skepticism about them as we should any model. But they are an important tool for understanding and even planning.
Indeed, our understanding gained from the study of (nonlinear) epidemic models has provided us with the most powerful tools we have for control and even eradication. As Hans Heesterbeek has noted, the idea that we could control malaria by targeting the mosquito vector of the disease is one that was considered ludicrous before Ross's development of the first epidemic model. The logic was essentially that there are so many mosquitoes that it would be absurdly impractical to eliminate them all. But the Ross model revealed that epidemics -- because of their nonlinearity -- have thresholds. We don't have to eliminate all the mosquitoes to break the malaria transmission cycle; we just need to eliminate enough to bring the system below the epidemic threshold. This was a powerful idea and it is central to contemporary public health. It is what allowed epidemiologists and public health officials to eliminate smallpox and it is what is allowing us to very nearly eliminate polio if political forces (black swans?) will permit.
Taleb's ludic fallacy (i.e., games of chance are somehow an adequate model of randomness in the world) is great. Quite possibly the most interesting and illuminating section of The Black Swan happens on p. 130 where he illustrates the major risks faced by a casino. Empirical data make a much stronger argument than do snide stereotypes. This said, Lund (2007) makes the important point that we need to ask what exactly is being modeled in any risk assessment or projection. One of the most valuable outcomes of any formalized risk assessment (or formal model construction more generally) is that it forces the investigator to be very explicit about what is being modeled. The output of the model is often of secondary importance.
Much of the evidence deployed in his books is what Herb Gintis has called "stylized facts" and, of course, is subject to Taleb's own critique of "hidden evidence." Because the stylized facts are presented anecdotally, there is no way to judge what is being left out. A fair rejoinder to this critique might be that these are trade publications meant for a mass market and are therefore not going to be rich in data regardless. However, the tone of the books – ripping on economists and bankers but also statisticians, historians, neuroscientists, and any number of other professionals who have the audacity to make a prediction or provide a causal explanation – makes the need for more measured empirical claims more important. I suspect that many of these people actually believe things that are quite compatible with the conclusions of both The Black Swan and Antifragile.
On Stress
The notion of antifragility turns on systems getting stronger when exposed to stressors. But we know that not all stressors are created equally. This is where the work of Robert Sapolsky really comes into play. In his book Why Zebras Don't Get Ulcers, Sapolsky, citing the foundational work of Hans Seyle, notes that some stressors certainly make the organism stronger. Certain types of stress ("good stress") improves the state of the organism, making it more resistant to subsequent stressors. Rising to a physical or intellectual challenge, meeting a deadline, competing in an athletic competition, working out: these are examples of good stresses. They train body, mind, and emotions and improve the state of the individual. It is not difficult to imagine that there could be similar types of good stressors at levels of organization higher than the individual too. The way the United States came together as a society to rise to the challenge of World War II and emerge as the world's preeminent industrial power comes to mind. An important commonality of these good stressors is the time scale over which they act. They are all acute stressors that allow recovery and therefore permit the subsequently improved performance.
However, as Sapolsky argues so nicely, when stress becomes chronic, it is no longer good for the organism. The same glucocorticoids (i.e., "stress hormones") that liberate glucose and focus attention during an acute crisis induce fatigue, exhaustion, and chronic disease when the are secreted at high levels chronically.
Any coherent theory of antifragility will need to deal with the types of stress to which systems are resistant and, importantly, have a strengthening effect. Using the idea of hormesis – that a positive biological outcome can arise from taking low doses of toxins – is scientifically hokey and boarders on mysticism. It unfortunately detracts from the good ideas buried in Antifragile.
I think that Taleb is on to something with the notion of antifragility but I worry that the policy implications end up being just so much orthodox laissez-faire conservatism. There is the idea that interventions – presumably by the State – can do nothing but make systems more fragile and generally worse. One area where the evidence very convincingly suggests that intervention works is public health. Life expectancy has doubled in the rich countries of the developed world from the beginning of the twentieth century to today. Many of the gains were made before the sort of dramatic things that come to mind when many people think about modern medicine. It turns out that sanitation and clean water went an awful long way toward decreasing mortality well before we had antibiotics or MRIs. Have these interventions made us more fragile? I don't think so. The jury is still out, but it seems that reducing the infectious disease burden early in life (as improved sanitation does) seems to have synergistic effects on later-life mortality, an effect is mediated by inflammation.
On The Academy
Taleb drips derision throughout his work on university researchers. There is a lot to criticize in the contemporary university, however, as with so many other external critics of the university, I think that Taleb misses essential features and his criticisms end up being off base. Echoing one of the standard talking points of right-wing critics, Taleb belittles university researchers as being writers rather than doers (echoing the H.L. Menken witticism "Those who can do; those who can't teach"). Skin in the game purifies thought and action, a point with which I actually agree, however, thinking that that university researchers live in a world lacking consequences is nonsense. Writing is skin in the game. Because we live in a quite free society – and because of important institutional protections on intellectual freedom like tenure (another popular point of criticism from the right) – it is easy to forget that expressing opinions – especially when one speaks truth to power – can be dangerous. Literally. Note that intellectuals are often the first ones to go to the gallows when there are revolutions from both the right and the left: Nazis, Bolsheviks, and Mao's Cultural Revolution to name a few. I occasionally get, for lack of a better term, unbalanced letters from people who are offended by the study of evolution and I know that some of my colleagues get this a lot more than I. Intellectuals get regular hate mail, a phenomenon amplified by the ubiquity of electronic communication. Writers receive death threats for their ideas (think Salman Rushdie). Ideas are dangerous and communicating them publicly is not always easy, comfortable, or even safe, yet it is the professional obligation of the academic.
There are more prosaic risks that academics face that suggest to me that they do indeed have substantial skin in the game. There is a tendency for critics from outside the academy to see universities as ossified places where people who "can't do" go to live out their lives. However, the university is a dynamic place. Professors do not emerge fully formed from the ivory tower. They must be trained and promoted. This is the most obvious and ubiquitous way that what academics write has "real world" consequences – i.e., for themselves. If peers don't like your work, you won't get tenure. One particularly strident critic can sink a tenure case. Both the trader and the assistant professor have skin in their respective games – their continued livelihoods depend upon their trading decisions and their writing. That's pretty real. By the way, it is a huge sunk investment that is being risked when an assistant professor comes up for tenure. Not much fun to be forty and let go from your first "real" job since you graduated with your terminal degree... (I should note that there are problems with this – it can lead to particularly conservative scholarship by junior faculty, among other things, but this is a topic for its own post.)
Now, I certainly think that are more and less consequential things to write about. I have gotten more interested in applied problems in health and the environment as I've moved through my career because I think that these are important topics about which I have potentially important things to say (and, yes, do). However, I also think it is of utmost importance to promote the free flow of ideas, whether or not they have obvious applications. Instrumentally, the ability to pursue ideas freely is what trains people to solve the sort of unknown and unforecastable problems that Taleb discusses in The Black Swan. One never knows what will be relevant and playing with ideas (in the personally and professionally consequential world of the academy) is a type of stress that makes academics better at playing with ideas and solving problems.
One of the major policy suggestions of Atifragile is that tinkering with complex systems will be superior to top-down management. I am largely sympathetic to this idea and to the idea that high-frequency-of-failure tinkering is also the source of innovation. Taleb contrasts this idea of tinkering is "top-down" or "directed" research, which he argues regularly fails to produce innovations or solutions to important problems. This notion of "top-down," "directed" research is among the worst of his various straw men and a fundamental misunderstanding of the way that science works. A scientist writes a grant with specific scientific questions in mind, but the real benefit of a funded research program is the unexpected results one discovers while pursuing the directed goals. As a simple example, my colleague Tony Goldberg has discovered two novel simian hemorrhagic viruses in the red colobus monkeys of western Uganda as a result of our big grant to study the transmission dynamics and spillover potential of primate retroviruses. In the grant proposal, we discussed studying SIV, SFV, and STLV. We didn't discuss the simian hemorrhagic fever viruses because we didn't know they existed! That's what discovery means. Their not being explicitly in the grant didn't stop Tony and his collaborators from the Wisconsin Regional Primate Center from discovering these viruses but the systematic research meant that they were in a position to discover them.
The recommendation of adaptive, decentralized tinkering in complex systems is in keeping with work in resilience (another area about which Taleb is scornful because it is the poor step-child of antifragility). Because of the difficulty of making long-range predictions that arises from nonlinear, coupled systems, adaptive management is the best option for dealing with complex environmental problems. I have written about this before here.
So, there is a lot that is good in the works of Taleb. He makes you think, even if spend a lot of time rolling your eyes at the trite stereotypes and stylized facts that make up much of the rhetoric of his books. Importantly, he draws attention to probabilistic thinking for a general audience. Too much popular communication of science trades in false certainties and the mega-success of The Black Swan in particular has done a great service to increasing awareness among decision-makers and the reading public about the centrality of uncertainty. Antifragility is an interesting idea though not as broadly applicable as Taleb seems to think it is. The inspiration for antifragility seem to lie in largely biological systems. Unfortunately, basing an argument on general principles drawn from physiology, ecology, and evolutionary biology pushes Taleb's knowledge base a bit beyond its limit. Too often, the analogies in this book fall flat or are simply on shaky ground empirically. Nonetheless, recommendations for adaptive management and bricolage are sensible for promoting resilient systems and innovation. Thinking about the world as an evolving complex system rather than the result of some engineering design is important and if throwing his intellectual cachet behind this notion helps it to get as ingrained into the general consciousness as the idea of a black swan has become, then Taleb has done another major service.